[2018 SCPC 2차 예선]
히스토그램
특정 데이터의 분포 및 특성을 분석하기 위해 흔히 히스토그램을 사용한다.
히스토그램은 일정한 간격으로 계급을 만들고 그에 속하는 데이터의 개수(도수)를 막대 그래프 등으로 표현하는 방법으로 나타난다.
히스토그램 분석 과정에서 그 형태가 들쭉날쭉하거나 너무 복잡하면 분석이 어렵기 때문에 이를 단순화하는 전처리 과정을 행하기도 한다.
이러한 단순화 과정 중에 하나는 주어진 히스토그램을 비감소(non-decreasing)하는 형태로 변형하는 것이다.
비감소 히스토그램이란 계급을 왼쪽에서 오른쪽으로 이동할 때, 각 계급에 해당하는 도수가 감소하지 않는 히스토그램을 말한다.
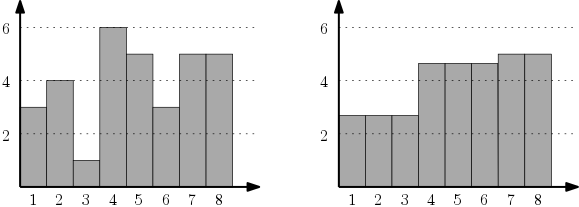
예를 들어 위의 그림에서는 두 개의 히스토그램을 보여주는데, 오른쪽은 비감소 히스토그램이며 왼쪽은 그렇지 않은 경우이다.
이 문제에서는 입력으로 히스토그램이 주어지면 이를 비감소 히스토그램으로 변환하고자 한다.
단, 변환된 결과물이 원래의 것과의 오차가 최소가 되도록 하는 것이 목표이다.
같은 계급의 집합 \(I\) 을 가지는 두 히스토그램 \(H\)와 \(H'\) 사이의 오차는 아래와 같은 수식으로 계산된다.
\(\sum_{i \in I} (H(i)-H'(i))^2\)
위에서 \(H(i)\)는 히스토그램 \(H\)에서의 계급 \(i\)의 도수이며, \(H'(i)\) 는 히스토그램 \(H'\)의 계급 \(i\)의 도수이다.
예를 들어, 위 그림에서의 왼쪽 히스토그램을 \(H\), 오른쪽 히스토그램을 \(H'\)라고 하면, \(H'(1)=H'(2)=H'(3)=8/3\) , \(H'(4)=H'(5)=H'(6)=14/3\) , \(H'(7)=H'(8)=5\)로 나타나며,
이때 두 히스토그램 사이의 오차는 정확히 \(84/9\) 가 된다.
계급의 개수가 \(N\)인 히스토그램이 입력으로 주어질 때, 이를 오차가 최소인 비감소 히스토그램으로 변환하고 이때의 오차 값을 출력하는 프로그램을 작성하시오.
단, 결과물인 비감소 히스토그램의 도수는 정수가 아닌 실수의 값을 가질 수 있다고 가정하시오.
- 제한시간: 전체 테스트 케이스는 30개 이하이며, 전체 수행 시간은 2초 이내. (Java 4초 이내)
제한 시간을 초과하면 제출한 소스코드의 프로그램이 즉시 종료되며,
그때까지 수행한 결과에서 테스트 케이스를 1개 그룹 이상 통과하였더라도 점수는 0점이 됩니다.
그러나, 제한 시간을 초과하더라도 테스트 케이스를 1개 그룹 이상 통과하였다면 '부분 점수(0< 점수< 만점)'를 받을 수 있으며,
이를 위해서는, C / C++ 에서 "printf 함수" 사용할 경우, 프로그램 시작부분에서 "setbuf(stdout, NULL);"를 한번만 사용하십시오.
C++에서는 "setbuf(stdout, NULL);"와 "printf 함수" 대신 "cout"를 사용하고, Java에서는 "System.out.println"을 사용하시면,
제한 시간을 초과하더라도 '부분 점수'를 받을 수 있습니다.
※ 언어별 기본 제공 소스코드 내용 참고
만약, 제한 시간을 초과하지 않았는데도 '부분 점수'를 받았다면, 일부 테스트 케이스를 통과하지 못한 경우 입니다.
- 메모리 사용 제한 : heap, global, static 총계 256MB, stack 1MB
- 제출 제한 : 최대 10회 (제출 횟수를 반영하여 순위 결정 → 동점자의 경우 제출 횟수가 적은 사람에게 높은 순위 부여)
입력
입력 파일에는 여러 테스트 케이스가 포함될 수 있다.
파일의 첫째 줄에 테스트 케이스의 개수를 나타내는 자연수 \(T\) 가 주어지고,
이후 차례로 \(T\) 개의 테스트 케이스가 주어진다. (\(1 ≤ T ≤ 30\))
각 테스트 케이스는 하나의 히스토그램 \(H\)가 입력으로 주어지며 정확히 두 줄로 이루어진다.
첫 줄에는 정수 \(N\) (\(1≤N≤1,000,000\)) 하나가 주어지며, 이는 \(H\)의 계급의 개수를 의미하며, 실제 \(H\)의 계급은 \(1,2,…,N\)이라고 가정한다.
두번째 줄에는 0이상 100이하의 정수 \(N\)개가 공백문자로 구분되어 주어지며, 각 계급의 도수인 \(H(1),H(2),…,H(N)\)을 의미한다.
- 점수 : 최대 10회 제출하여 취득한 각각의 점수 중에서 최대 점수 (만점 300점)
주어지는 테스트 케이스 데이터들의 그룹은 아래와 같으며,
각 그룹의 테스트 케이스를 모두 맞추었을 때 해당되는 부분 점수를 받을 수 있다.
ㆍ 그룹 1 (58 점) : 이 그룹의 테스트 케이스에서는 \(N≤500\)이다.
ㆍ 그룹 2 (89 점) : 이 그룹의 테스트 케이스에서는 \(N≤5,000\)이다.
ㆍ 그룹 3 (153 점) : 이 그룹의 테스트 케이스에서는 별도의 제한이 없다.
출력
각 테스트 케이스의 답을 순서대로 표준출력으로 출력하여야 하며,
각 테스트 케이스마다 첫 줄에는 “Case #C”를 출력하여야 한다.
이때 C는 테스트 케이스의 번호이다.
그 다음 줄에 입력으로 주어진 히스토그램 \(H\)에 대해 오차가 최소인 비감소 히스토그램을 찾고 이때의 오차 값을 실수 형태로 출력하시오.
단, 정확한 값으로부터 \(10^{-9}\) 만큼의 절대오차 혹은 상대오차를 허용하여 정답으로 처리한다.
입출력예
| 입력 |
|---|
| 2 8 3 4 1 6 5 3 5 5 10 0 1 5 6 8 8 8 9 12 15 |
| 출력 |
|---|
| Case #1 9.333333333 Case #2 0.000000000 |